RESS (Responsive Web Design + Server Side Components) explained

Head of Technology
3 minute read
Responsive design, adaptive design, or responsive web design & server-side (RESS)... what are they and which should you choose? Get the best of both worlds with RESS.
When building a new website, the basic approach has been to go either with Adaptive Web Design (AWD) or Responsive Web Design (RWD). But there's another emerging option: RESS (Responsive web design + Server Side).
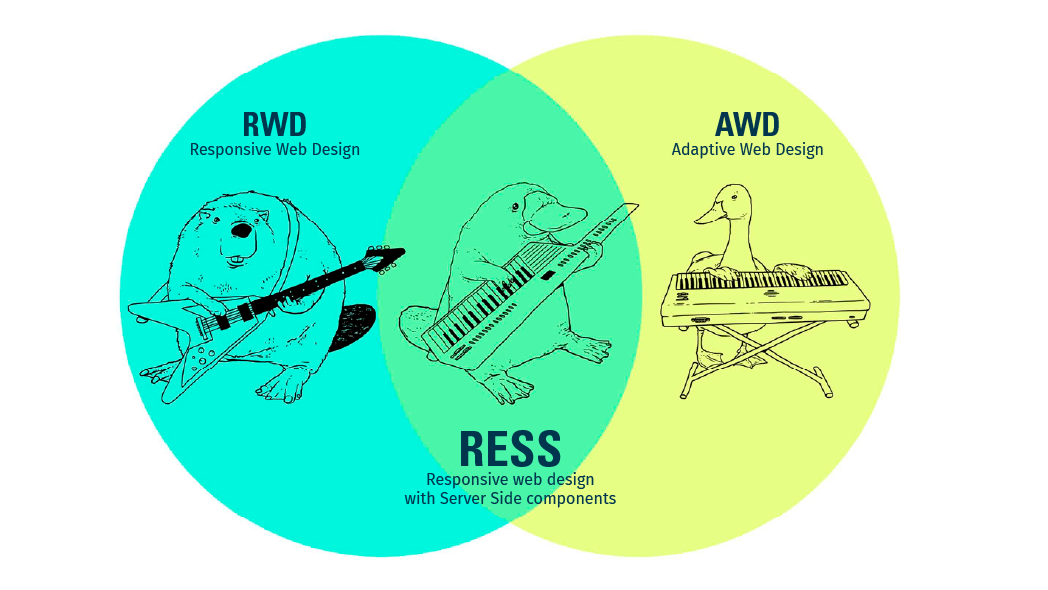
Firstly though, what are Responsive Web Design and Adaptive Web Design?
- RWD makes use of flexible webpage layouts and it detects the user's screen size so that it can change the layout accordingly.
- The AWD approach has predefined templates and media for desktop and another set for mobile
What is RESS?
RESS is a combination of RWD and AWD (or dynamically serving content). It aims to combine the advantages of both adaptive and responsive at the same time by using server side logic to serve different content dynamically based on the user agent and client side technologies.
Responsive websites maintain a single URL structure; however, adaptive sites usually change the url https://m.something.com or https://something.mob (meaning 2 sites with 2 x SEO effort). RESS means 1 site for all devices.
What are the advantages with RESS?
An average webpage is now about 1703 KB, and so over mobile connections, a responsive solution might still be quite slow. Large images set to ‘not visible’ on mobile are still being served because the small screen is still fetching all the content in most browsers.
A responsive site just inspects the width of the viewport, not the actual resolution to determine if it’s a phone. It doesn't check the capabilities of the device to see if features like touch or audio are present. Just because you have a width of 640 px doesn’t mean that the interface should be touch-oriented. RESS can help you overcome these difficulties compared to responsive.
A word of warning
If you have a global site that is highly dependent on CDN like Akamai, the use of http-vary will lead to Akamai not caching all the combinations of your content for you. The variation of all combinations of content with browser versions might take too much space.
MALE SPEAKER: Today's question comes from Christian in
Madrid, who asks, "What's Google's position about
continuing to recommend the HTTP Vary User-Agent header
for specific mobile websites after big players like Akamai
said they don't cache the URLs that include it?
Would you still recommend using it?" OK, this is a
pretty detailed topic, and it's pretty esoteric, so let's
see if we can unpack it and try to explain
what's going on there.
So first off, what's caching?
Well, if you ask for a web page, and then you ask for the
exact same web page three seconds later, why do all the
work to re-compute what that web page might look like if
you're doing a dynamic URL when you could save that
content and just return the same content back to users?
Now, you might need to re-compute that data once an
hour or once a day or something like that, but once
you've done the work to compute what a web page should
look like, oftentimes, you can cache it.
And so in the case when you're hitting a web server--
Facebook, Google, whatever--
if we've computed the search results for Britney Spears or
something like that, and somebody else asks, what are
the web results for Britney Spears one millisecond later,
we can usually just cache that and show them the same search
results back or something along those lines.
So caching is very helpful.
It helps reduce the load on web servers.
So now let's get into the problem that sometimes, the
user is doing the query from the desktop, and sometimes the
user is doing the query from a mobile site.
Well, you'd hate to cache the desktop site, and then when
the user asks for the same page from a smartphone or
something like that, for them to get the desktop page back
when they should get the smartphone page back.
So there's a way that you can do that.
You can handle caching by using the HTTP
Vary User-Agent header.
And what that says is if you're a cache, whether you're
on the server side, Varnish, something like that, maybe
you're the ISP, or whether you're a Content Delivery
Network, a CDN like Akamai, there are ways that you can
specify what is saved to cache.
And so if there's an HTTP header that says things can
vary by user agent-- so Chrome versus a mobile, smartphone
user agent--
then the cache in theory can accommodate that.
They can say, OK, I'll save up to however many copies there
are as I see different user agents.
So where does that lead to a problem?
Well, there's a lot of different user agents, and I
can certainly understand if somebody like Akamai would
say, well, if there's 600 user agents, we don't want to save
600 copies of this page.
So I think what Akamai has said is that they will not
cache a page that uses the HTTP Vary header if it's only
by user agent or something like that.
Because there can be so many different versions, they're
worried about serving the wrong version or using up too
much storage space.
So given that, should people still continue to use the HTTP
Vary header?
Well, I think the answer is yes because there's still lots
and lots of opportunities where server side caches, ISP
caches, all kinds of other caches could still make use of
that information and could still do something smart to
avoid doing a lot of extra work or computation or
something along those lines.
So individual Content Delivery Networks might make a decision
about how they would treat that specific header and
whether they would do something differently.
But it's still a good idea, if you have a website, to try to
send that information along so that the various caches
between you and the user can try to do something smart.
Because if you take that out completely, then they don't
have any information, and they just aren't able to be able to
handle that.
So in general, in terms of Google indexing, it's not
apparent to us whether a URL can return different content
based on the user agent, and so we actually do look at the
HTTP Vary header in order to help us assess whether a page
might be targeted both to desktop and to mobile.
So that's another reason to use it.
And I would recommend that people continue to use it
because if you do, then that can help us figure out, oh,
this particular URL can return different content to desktop
and to mobile.
So it's kind of a complicated issue.
Everybody's trying to do their best, but I think we do still
recommend that you continue to use the HTTP Vary by
User-Agent header if you're serving different content to
desktop versus smartphone or something like that.
That's a pretty technical webmaster video for today, but
I hope it all makes sense.
Thanks.
But there are other solutions to improve things like dynamic DNS based on location or cloud services. But that’s another story, so let’s take that in a future blog post instead!
Conclusions
In most cases the responsive approach will continue to be the most common implementation over the next few years, mostly because of budgets. But when load time and the desire for a truly great mobile experience is considered to be equally important we will see more RESS solutions.
We will also see a lot more experimenting with RESS in libraries and in CMS in the next couple of years. I think it will be a more incremental transformation when CMS platforms like WordPress, EPiServer and Umbraco start adapting to the RESS idea. A good example of a nice component is the Mobile detect library that is available for many of the popular CMS platforms like WordPress, Magento and Joomla.
Interested in more RESS information?
- Mobile Detect - https://github.com/serbanghita/Mobile-Detect#3rd-party-modules--submit-new
- Good RESS Presentation - https://prezi.com/tgh0nmubj0xs/ress-responsive-design-serverside-components/
- Lightening your responsive website design with RESS - https://deviceatlas.com/resources/whitepapers
- Modernizr - https://modernizr.com/docs/#installing